There are differnt types of TDM Approaches and Best Practces that can be followed, Some of them are:
Data Provisioning Approach
Data Masking
Data Masking creates structurally similar but dummy data that can be used for QE and development activities in non-production environments. Having Data Masked data in a non-production environment will prevent the exposure of sensitive data. IT environments have used production data for testing, development, and enhancement. This poses a risk of customers’ data being exposed. To comply with mandates, it must mask the production data used in the test and development environments. The TDM team should perform Data Masking before the masked data is provisioned/utilized by the QE team.
a) Data elements to be masked
Element-wise sensitivity should cover all the required fields for all the databases across the organization. These elements should be identified and verified by SME / IT security team. The TDM team should provide masking solutions to de-identify the data elements based on the pre-approved data masking rule by the SME.
b) Methodology for masking projects
Masking projects conducted by the central TDM for the data stores should follow the methodology described in this section. The method consists of 4 phases. This same process applies to data subsets and data generation based on their respective areas of requirement.
Initiation
- Scoping: Finalize the list of applications in scope.
- Point of contact: Identify the point of contact (QE/Technical/Owner/DBA/Environment Team).
- Project objectives: Defines the data requirements and success criteria.
- The Environment needs Environment requirements and dependencies
Analyze & Design
- Analyze: Analyze end-to-end data flow for dependencies and referential integrities between tables and their related columns
- Data targeted for masking: Identification of the data to be masked, their sizes, complexity, and the actual volume of test data to be masked
- Data targeted for masking: Identification of the data to be masked, their sizes, complexity, and the actual volume of test data to be masked
- Technical Approach: How the masking will be accomplished against each identified data store, including process flows
- Physical Architecture: Representation of the physical data flow regarding environments and masking points
- Dependencies: Dependencies for delivery from groups outside of TDM
- Operations Plan: Deployment plan into the environments and run schedules
Configure & Build
- Connection Setup: Set up target data store (database/schema) connections and import metadata
- Map and Mask: This phase includes deliverables like mapping documents for masking rules and design executables to conduct the data masking
- Document Columns: Create a mapping sheet to know what columns should get masked with the masking rule. These rules will be segregated based on re-usable (global) and project-specific (local)
- Design: Design masking rule
- Configure: Grouping of tables to mask data. Here, dependency is all the referential integrity between tables DBA shares and the data provider understands. After this, develop a strategy to pull the table to mask in groups
Execute
- Execution: Execute the implementation according to the configuration plan where table groups are created according to referential integrity
- Transition: Transition the “Run” knowledge and turn it over to BAU
Summarized activities to be followed
- Collect database-level referential integrity with the help of DBA
- Collect the data masking requirement per table per column
- Finalize the business rule per column
- Signoff document from SME before proceeding to the configuration of masking rules
- Develop and apply the masking rules to the required columns
The diagram below shows the approach to data masking:
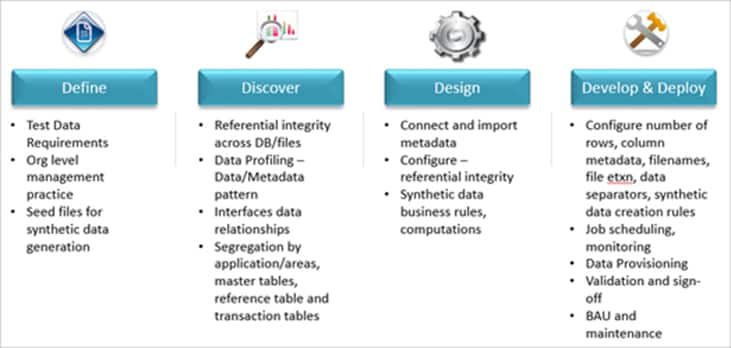
Below mentioned masking types are available:
Key Masking: Masks the key value and produces deterministic results for input key value, masking rule and seed value.
Substitution Masking: Replaces the input column data with a value from a dictionary file or table
Dependent Masking: Replaces the value of the input column based on the value of another column
Random Masking: Replaces input column value with random values for the same source data and masking rule
Expression Masking: Uses Informatica transformation functions to mask and replace data in source columns
Special Mask formats: Replaces realistic fake values for fields like credit cards, addresses, social security numbers etc.
No Masking: The default is no masking.
Data Subset
Data sub-setting creates a smaller, referentially correct copy of a larger database. After subsetting, the cut-down database remains perfectly usable. The data is referentially correct and internally consistent. At this stage, the target environment’s total size is much more manageable.
Subsetting ensures extracting small, more intelligent subsets from production. This allows TDM to quickly provide teams with more manageable sets of consistent, referentially intact data for testing. It also minimizes the risk of exposing sensitive records.
The data can be sub-set based on functional needs by applying data filters. It will be built based on the physical grouping of application tables. The diagram below shows the approach to sub-set the data.
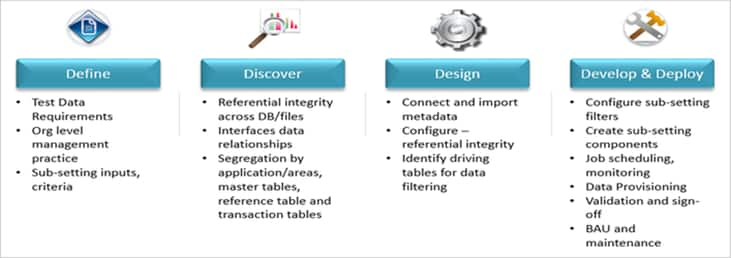
Core requirements for subset criteria should be driven by below factors:
Infrastructure (Space) constraints and costs while managing test environments
The right sample of test data is available for all scenarios to make sure maximum test data coverage
The key steps involved are outlined in the table below:
| Operating Systems | Supported Operating Systems |
|---|---|
Supported Data Sources |
Ex: Oracle 11g, IBM DB2400 iSeries V7R1 etc. |
Installation Considerations |
TDM Subset can reside on the same system, or does it require any other components. |
Subset Procedure |
|
To access the larger data set stored in the data source and apply subset rules to extract small, more intelligent data subsets |
Establish database connection(s) |
Create extract definitions |
|
(Optional) Prepare subset schema |
|
Create a load group to move data based on driving tables |
|
Run extracts |
|
Summarized activities to be followed
- Collect database-level referential integrity with the help of DBA
- Collect driving tables and the group of tables for which data needs to be filtered
- Collect the data subset requirement per table
- Finalize the data filter rule per column
- Signoff document from SME before proceeding to the configuration of filter rules
- Develop and apply the filter rules to the required columns
Synthetic Generation
- Eliminate the risk of data breach by creating production-like data without sensitive content
- Reduce the infrastructure footprint by increasing test data coverage
- Enhance existing subsets of production data with rich & sophisticated sets of synthetic data
- Create large volumes of data for non-functional testing like performance and load tests
- Simulate wide varieties of data scenarios that include data scenarios not currently available in production
- Synthetic data generation services are ideal for transactional data to provision quicker & reliable datasets
Following synthetic data generation techniques may be explored and considered for various test data use cases:
a) Data Generation Techniques
Data Model-based generation: This approach allows users to create complex datasets based on business rules and constraints. Developers build/replicate data models and configure generation rules for each data domain.
Users can assign data elements with the respective domain so that the appropriate generation rule is called out at run time. The most widely used generation rules are:
Random
Lookup
Regular Expressions
Synthetic data is generated at the data source level.
Automated generation via application interfaces: This is a widely used data generation technique. It is based on the data injection via application interfaces (UI) or passing parameters to API to suit the test data requirement.
Synthetic data is keyed into the application interfaces via GUI or API. The process is automated so that manual intervention is reduced.
The approach to delivering synthetic data follows the fulfilment process below:
| Activity | Details |
|---|---|
Assess Test Data generation requirements |
|
Master data vs Transactional data |
Identify and categorize generation services based on master data vs transactional |
Seed file |
Create the seed files for the data dedicated to enterprise level (e.g., Region, Country, type of business product etc.) data set and can be used repeatedly due to its use in multiple tables. |
Document signoff |
This document has details on each table for which data is to be generated. A tabular display should have details on
|
Summarized activities to be followed: Below activities should be followed as a part of the test data generation activity:
Collect database-level referential integrity with the help of DBA.
Collect the data requirement per table per column.
Finalize the business rule per column.
Finalize the number of records to be generated.
Sign off a document from SME before configuring data generation business rules.
Seed file creation to baseline client-specific data used repeatedly across tables.
Develop and apply the business rule per column and configure the number of records generated.
The diagram below shows the approach to data generation:
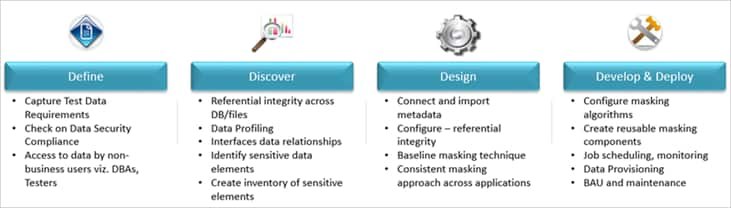

TDM Best Practices
Minimize reliance on test data. Test data requires careful and ongoing maintenance. You must update or re-create related test data as your APIs and interfaces evolve. This process represents a cost that can negatively impact team velocity. Hence, minimizing the amount of test data needed to run automated tests is good practice.
Isolate test data. Run your tests in well-defined environments with controlled inputs and expected outputs that can be compared to actual results. Ensure that data consumed by a particular test is explicitly associated with that test and isn’t modified by other tests or processes. Wherever possible, your tests should create the necessary state as part of the setup using the application’s APIs. Isolating your test data is also a prerequisite for running tests in parallel.
Minimize reliance on test data stored in databases. Maintaining test data stored in databases can be particularly challenging for the following reasons:
Poor test isolation. Databases store data durably; any changes to the data will persist across tests unless explicitly reset. Less reliable test inputs make test isolation more complex and can prevent parallelization.
Performance impact. Speed of execution is a key requirement for automated tests. Interacting with a database is typically slower and more cumbersome than interacting with locally stored data. Favour in-memory databases where appropriate.
Make test data readily available. Running tests against a copy of a complete production database introduces risk. It can be challenging and slow to get the data refreshed. As a result, the data can become out of date. Production data can also contain sensitive information. Instead, identify relevant sections of data that the tests require. Export these sections regularly and make them readily available for tests.
Roles & Responsibilities
TDM Team
| Role | Responsibility |
|---|---|
Test Data Architect |
|
Test Data Analyst |
|
Key Stakeholders:
| Team | Responsibilities |
|---|---|
Data Migration Team |
|
Development |
|
QE Specialist |
|
Information Security Team |
|
Release Management |
|
Entry & Exit Criteria:
| Phase | Entry | Exit |
|---|---|---|
Assessment / Intake |
|
|
Test Planning |
|
|
Test Design |
|
|
Test Execution |
|
|
Suspension & Resumption Criteria
Suspension Criteria
All test data provisioning efforts should adhere to the scheduled timelines unless one of the following critical dependencies is altered.
There are significant bottlenecks/showstoppers for which the test data provisioning activity cannot be continued.
In case of Known / Unknown test environment downtime.
External dependency on the project is unable to provide required triggers/data inputs may cause halting the test data activities. For example, a) SME availability to provide the data model or clarify a critical query on a data model, b) Source environment shut down.
Hardware/software not available at the time indicated in the project schedule.
Any unplanned holiday shuts down both developments (IT) and testing.
Resumption Criteria
The data provisioning activity will be resumed once the bottlenecks/showstoppers issues are settled.
Once the test environment is up, the test data activity will be resumed.
Test data provisioning will be resumed once the TDM team receives the required triggers/data inputs.
Test data provisioning will be resumed once the necessary hardware/software is available.
Typical Response Time for Data Request:
Definition of Data requests
A data request is considered “Simple” when
a) It is a repeat request,
b) The number of apps involved is not more than 2
c) Reasonable Volume of Data is requested.
A data request is “Medium” when
a) It is a new request raised for the first time
b) The number of apps involved is not more than 2
c) A reasonable Volume of data is requested
A data request is “Complex” when
a) It is a new request raised for the first time
and b) More than two applications are involved.
c) Multiple batch runs are involved.
d) Volume of data requested is high.
Response Times:
| Data Request Type | Turnaround Time |
|---|---|
Simple |
1-3 business days |
Medium |
3-5 business days |
Complex |
5–7 business days |



