Overview
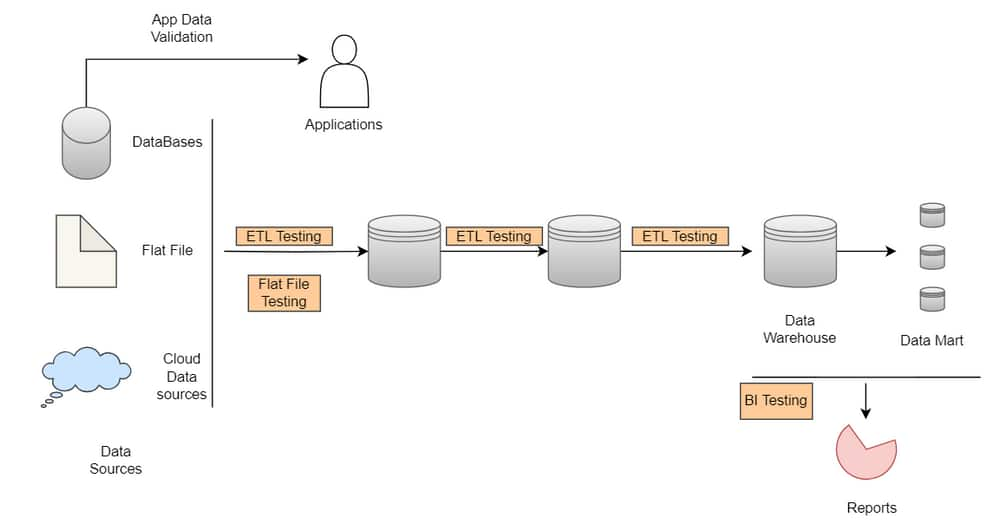
Data Testing is different from application testing because it requires a data-centric testing approach. Some of the Key elements in Data Testing are
Data testing involves comparing large volumes of data, typically millions of records.
Data that needs to be compared can be in heterogeneous data sources such as databases, flat files etc.
Data is often transformed, which might require complex SQL queries to compare the data.
Data Warehouse testing is very much dependent on the availability of test data with different test scenarios.
BI tools such as OBIEE, Cognos, Business Objects and Tableau generate reports on the fly based on a metadata model. Testing various combinations of attributes and measures can be a huge challenge.
The volume of the reports and the data can also make it very challenging to test these reports for regression, stress and functionality.
Data Testing Categories
ETL (Extract Transform Load) Testing
Flat File Testing
Business Intelligence (BI) Testing
Application Transactional Database Testing

Metadata Testing
Metadata Testing aims to verify that the table definitions conform to the data model and application design specifications.
Data Type check
Verify that the table and column data type definitions are as per the data model design specifications.
Data Length Check
Verify that the length of database columns is as per the data model design specifications.
Index / Constraint Check
Verify that proper constraints and indexes are defined on the database tables as per the design specifications.
Metadata Naming Standards Check
Verify that the names of the database metadata, such as tables, columns, and indexes, are as per the naming standards.
Metadata Check across Environments
Compare table and column metadata across environments to ensure that changes have been migrated appropriately.

Data Completeness Test
The purpose of Data Completeness tests is to verify that all the expected data is loaded into the target from the source. Some of the tests that can be run are Compare and Validate counts, aggregates (min, max, sum, avg) and actual data between the source and target.
Record Count Validation
Compare the count of records of the primary source table and target table. Check for any rejected records.
Column Data Profile Validation
Column or attribute-level data profiling is an effective tool for comparing source and target data without comparing the entire data. It is similar to comparing the checksum of your source and target data. These tests are essential when testing large amounts of data.
Compare Entire Source and Target Data
Compare data (values) between the flat file and target data, effectively validating 100% of the data. In regulated industries such as finance and pharmaceutical, 100% data validation might be a compliance requirement. It is also a key requirement for data migration projects. However, performing 100% data validation is a challenge when large volumes of data are involved. This is where ETL testing tools such as ETL Validator can be used because they have an inbuilt ELV engine (Extract, Load and Validate) capable of comparing large values of data.
Data Quality Test
The purpose of Data Quality tests is to verify the accuracy of the data. Data profiling is used to identify data quality issues and the ETL design to fix or handle these issues. However, source data keeps changing, and new data quality issues may be discovered even after the ETL is used in production. Automating the data quality checks in the source and target system is an important aspect of ETL execution and testing.
Duplicate Data Checks
Look for duplicate rows with the same key column or a unique combination of columns per business requirements. Example: Business requirement says that a combination of First Name, Last Name, Middle Name and Data of Birth should be unique.
Data Validation Rules
Many database fields can contain a range of values that cannot be enumerated. However, there are reasonable constraints or rules that can apply to detect situations where the data is clearly wrong. Instances of fields containing values violating the validation rules defined represent a quality gap that can affect ETL processing.
Data Integrity Checks
This measurement addresses “keyed” relationships of entities within a domain. These checks aim to identify orphan records in the child entity with a foreign key to the parent entity.
Count of records with null foreign key values in the child table.
Count of invalid foreign key values in the child table that do not have a corresponding primary key in the parent table.

Data Transformation Tests
Data transformation happens during the ETL process so that it can consume by applications on the target system. Transformed data is generally important for the target systems, so it is important to test transformations. Two approaches for testing transformations are white box testing and black box testing.
Transformation testing using the White Box approach
White box testing is a testing technique that examines the program structure and derives test data from the program logic/code. Transformation testing involves reviewing the transformation logic from the mapping design document and the ETL code to come up with test cases. The steps to follow are
Review the source to target mapping design document to understand the transformation design.
Apply transformations on the data using SQL or a procedural language such as PLSQL to reflect the ETL transformation logic.
Compare the results of the transformed test data with the data in the target table.
The advantage of this approach is that the test can be rerun easily on larger source data. The disadvantage of this approach is that the tester has to implement the transformation logic.
Transformation testing using the Black Box approach
Black-box testing is a software testing method that examines an application's functionality without peering into its internal structures or workings. For transformation, testing involves reviewing the transformation logic from the mapping design document and setting up the test data appropriately. The steps to follow are listed below:
Review the requirements document to understand the transformation requirements.
Prepare test data in the source systems to reflect different transformation scenarios.
Come with the transformed data values or the expected values for the test data from the previous step.
Compare the results of the transformed test data in the target table with the expected values.
The advantage of this approach is that the transformation logic does not need to implement during the testing. The disadvantage of this approach is that the tester needs to set up test data for each transformation scenario and come up with the expected values for the transformed data manually.

Incremental Data Test
ETL process is designed to run in a Full mode or Incremental mode. When running in Full mode, the ETL process truncates the target tables and reloads all (or most) of the data from the source systems. Incremental ETL only loads the data that changed in the source system using some kind of change capture mechanism to identify changes. Incremental ETL is essential to reducing the ETL run times, and it is an often-used method for updating data on a regular basis. Incremental ETL testing aims to verify that updates on the sources are getting loaded into the target system properly.
While most of the data completeness and data transformation tests are relevant for incremental ETL testing, a few additional tests are relevant. First, setting up test data for updates and inserts is key for testing Incremental ETL.
Duplicate Data Checks
When a source record is updated, the incremental ETL should be able to lookup for the existing record in the target table and update it. If not, this can result in duplicates in the target table.
Compare Data Values
Verify that the changed data values in the source are reflected correctly in the target data. Typically the records updated by an ETL process are stamped by a run ID or a date of the ETL run. This data can be used to identify the newly updated or inserted records in the target system. Alternatively, all the records that got updated in the last few days in the source and target can be compared based on the incremental ETL run frequency.
Data Denormalization Checks
Denormalization of data is quite common in a data warehouse environment. Source data is denormalized in the ETL to improve the report performance. However, the denormalized values can get stale if the ETL process is not designed to update them based on changes in the source data.
Slowly Changing Dimension Checks
While there are different types of slowly changing dimensions (SCD), testing and SCD Type 2 dimension is presently a unique challenge since there can be multiple records with the same natural key. Type 2 SCD is designed to create a new record whenever there is a change to a set of columns. The latest record is tagged with a flag, and there are start date and end date columns to indicate the period of relevance for the record. Some of the tests specific to a Type 2 SCD are listed below:
Is a new record created every time there is a change to the SCD key columns, as expected?
Is the latest record tagged as the latest record by a flag?
Are the old records end dated appropriately?
ETL Regression testing
ETL Regression testing aims to verify that the ETL produces the same output for a given input before and after the change. Any differences need to be validated whether are expected as per the changes. Changes to Metadata Track changes to table metadata in the Source and Target environments. Often changes to source and target system metadata changes are not communicated to the QE and Development teams resulting in ETL and Application failures. This check is important from a regression testing standpoint.
End-to-End Integration Test
Once the data is transformed and loaded into the target by the ETL process, it is consumed by another application or process in the target system. The consuming application is a BI tool for data warehouse projects such as OBIEE, Business Objects, Cognos or SSRS. For a data migration project, data is extracted from a legacy application and loaded into a new application. In a data integration project, data is shared between two different applications, usually regularly. ETL integration testing aims to perform end-to-end testing of the data in the ETL process and the consuming application.
End-to-End Data Testing
Integration testing of the ETL process and the related applications involves the following steps:
Set up test data in the source system.
Execute the ETL process to load the test data into the target.
View or process the data in the target system.
Validate the data and application functionality that uses the data.
ETL Performance Testing
The performance of the ETL process is one of the key issues in any ETL project. Often development environments do not have enough source data for performance testing of the ETL process. This could be because the project has just started, the source system only has a small amount of test data, or production data has PII information, which cannot be loaded into the test database without scrubbing. The ETL process can behave differently with different volumes of data.
Flat File Testing

File Ingestion Testing
When data is moved using flat files between enterprises or organizations within an enterprise, it is important to perform a set of file ingestion validations on the inbound flat files before consuming the data in those files.
File Name Validation
Files are FTP’ed or copied over to a specific folder for processing. These files usually have a specific naming convention so that the process consuming the file is able to understand the contents and date. From a testing standpoint, the file name pattern needs to be validated to verify that it meets the requirement.
Size and Format of the Flat Files
Although flat files are generally delimited or fixed in width, having a header and footer is common in these files. Sometimes, these headers have a row count that can be used to verify that the file contains the entire data as expected.
Some of the relevant checks are:
Verify that the size of the file is within the expected range where applicable.
Verify that the header, footer and column heading rows have the expected format and have the expected location within the flat file.
Perform any row count checks to crosscheck the data in the header with the values in the delimited data.
File Arrival, Processing and Deletion Times
Files arrive periodically in a specific network folder or an FTP location before getting consumed by a process. Usually, specific requirements need to be met regarding the file arrival time, order of arrival and retaining them.

Data Type Testing
Data Type testing aims to verify that the type and length of the data in the flat file are as expected.
Data Type Check
Verify that the type and format of the data in the inbound flat file match the expected data type for the file. For date, timestamp and time data types, the values are expected to be in a specific format so that they can be parsed by the consuming process.
Data Length Check
The length of the string and the number of data values in the flat file should match the maximum allowed length for those columns.
Not Null Check
Verify that any required data elements in the flat file have data for all the rows.
Data Quality Testing
The purpose of Data Quality tests is to verify the accuracy of the data in the inbound flat files.
Duplicate Data Checks
Check for duplicate rows in the inbound flat file with the same unique key column or a unique combination of columns as per business requirements.
Reference Data Checks
Flat file standards may dictate that the values in certain columns should adhere to values in a domain. Verify that the inbound flat file values conform to reference data standards.
Data Validation Rules
Many data fields can contain a range of values that cannot be enumerated. However, there are reasonable constraints or rules that can be applied to detect situations where the data is clearly wrong. Instances of fields containing values violating the validation rules defined represent a quality gap that can impact inbound flat file processing.
Data Integrity Checks
This check addresses “keyed” relationships of entities within a domain. The goal is to identify orphan records in the child entity with a foreign key to the parent entity.
Count of records with null foreign key values in the flat file.
Count of invalid foreign key values in the flat file that does not have a corresponding primary key in the parent flat file or database table.

Data Completeness Testing
Data in the inbound flat files are generally processed and loaded into a database. In some cases, the output may also be another flat file. Data Completeness tests verify that all the expected data is loaded in the target from the inbound flat file. Some of the tests that can be run are: Compare and Validate counts, aggregates (min, max, sum, avg) and actual data between the flat file and target.
Record Count Validation
Compare the count of records of the flat file and database table. Check for any rejected records.
Column Data Profile Validation
Column or attribute-level data profiling is an effective tool for comparing source and target data without comparing the entire data. It is similar to comparing the checksum of your source and target data. These tests are essential when testing large amounts of data.
Some of the common data profile comparisons that can be done between the flat file and target are:
Compare unique values in a column between the flat file and the target.
Compare max, min, avg, max length, and min length values for columns depending on the data type.
Compare null values in a column between the flat file and target.
For important columns, compare data distribution (frequency) in a column between the flat file and the target.
Compare Entire Flat File and Target Data
Compare data (values) between the flat file and target data, effectively validating 100% of the data. In regulated industries such as finance and pharma, 100% data validation might be a compliance requirement. It is also a key requirement for data migration projects. However, performing 100% data validation is a challenge when large volumes of data are involved. This is where ETL testing tools such as ETL Validator can be used because they have an inbuilt ELV engine (Extract, Load, Validate) capable of comparing large values of data.

Application Transactional Database Testing
Databases are key components of most software applications. Application testing is well documented and important for the success of the project, but often there is little or no testing done for the development done in databases. Database testing is the process of validating that the metadata (structure) and data stored in the database meet the requirement and design. Database Testing is important because it helps identify data quality and application performance issues that might otherwise get detected only after the application has been live for some time.
What do we test when testing an application transactional database?
Metadata Testing
Metadata Testing aims to verify that the table definitions conform to the data model and application design specifications.
Data Type check
Verify that the table and column data type definitions are as per the data model design specifications.
Data Length Check
Verify that the length of database columns is as per the data model design specifications.
Index / Constraint Check
Verify that proper constraints and indexes are defined on the database tables as per the design specifications.
Metadata Naming Standards Check
Verify that the names of the database metadata, such as tables, columns, and indexes, are as per the naming standards.
Metadata Check across Environments
Compare table and column metadata across environments to ensure that changes have been migrated appropriately.
Data Quality Testing
The purpose of Data Quality tests is to verify the accuracy and quality of the data. Data profiling is used to identify data quality issues in production systems once the application has been live for some time. However, database testing aims to automate the data quality checks in the testing phase.
Duplicate Data Checks
Look for duplicate rows with the same key column or a unique combination of columns per business requirements.
Data Validation Rules
Many database fields can contain a range of values that cannot be enumerated. However, there are reasonable constraints or rules that can be applied to detect situations where the data is clearly wrong. Instances of fields containing values violating the validation rules defined represent a quality gap that can affect ETL processing.
Data Integrity Checks
This measurement addresses “keyed” relationships of entities within a domain. These checks aim to identify orphan records in the child entity with a foreign key to the parent entity.
Reference Data Testing
Many database fields can only contain a limited set of enumerated values. Instances of fields containing values not found in the valid set represent a quality gap that can affect processing. Verify that Data confirms to reference Data Standards Data model standards dictate that the values in certain columns should adhere to values in a domain.
Compare Domain Values across Environments
One of the challenges in maintaining reference data is to verify that all the reference data values from the development environments have been migrated properly to the test and production environments.
Track Reference Data Changes
Baseline reference data and compare it with the latest reference data to validate the changes.
Database Regression Testing
Database Regression testing aims to identify any issues that might occur due to changes in the database metadata, procedures or system upgrades. The key for regression testing of the Databases, particularly in an agile development environment, is to organize test cases into test plans (or test suites) and execute them as and when needed based on the changes in the application or product.
Database Integration Testing
When an application is tested from the UI, the database procedures and tables are accessed and tested as well. Integration testing aims to validate that the database tables are being populated with the expected data based on input provided in the application.
Integration testing of the database and the related applications involves the following steps:
Review the application UI to database attribute with mapping document. Prepare one if missing.
Run tests in the application UI tracking the test data input.
Verify that the data loaded into the database tables matches the input test data.
Database Performance Testing
Database performance is an important aspect of application performance testing. Often development environments do not have enough data for performance testing of the database. This could be because the project has just started and the database only has a small amount of test data or production data has PII information, which cannot be loaded into the test database without scrubbing. The application can behave differently with different volumes of data. Setting up realistic test data using one of the following strategies is key to performance testing.
Mask and refresh test data in the test environments from the production environment.
Generate larger volume of test data using data generation tools
Data Transformation Testing
Data in the inbound Flat File is transformed by the consuming process and loaded into the target (table or file). It is important to test the transformed data. Two approaches for testing transformations are white box testing and black box testing.
Step 1
- Review the transformation design document.
Step 2
- Prepare test data in the flat file to reflect different transformation scenarios.
Step 3
- Apply transformations on the flat file data using SQL or a procedural language such as PL / SQL to reflect the ETL transformation logic.
Step 4
- Compare the results of the transformed data with the data in the target table or target flat file.
End-to-End Data Testing of Flat File Ingestion
Integration testing of the inbound flat file ingestion process and the related applications involves the following steps:
Step 1
- Estimate expected data volumes in each source flat file for the consuming process for the next 1-3 years.
Step 2
- Set up test data for performance testing either by generating sample flat files or getting sample flat files.
Step 3
- Execute the flat file ingestion process to load the test data into the target.
Step 4
- Executing the flat file ingestion process again with large data in the target tables to identify bottlenecks.
Business Intelligence (BI) Testing
When a new report or dashboard is developed for consumption by other users, performing a few checks to validate the data and design of the included reports is important.
BI Functional Testing
Report or Dashboard Design Check
Verify that the new report or dashboard conforms to the report requirement/design specifications. Some of the items to check are :
Verify that the report or dashboard page title corresponds to the content of the reports.
For reports with charts, the axis should be labelled appropriately.
The data aggregation level in the reports should be as per the report requirements.
Verify that the report or dashboard page design conforms to the design standards and best practices.
Validate the presence and functionality of the report download and print options.
Where applicable, verify that the report help text exists and is appropriate for the report content.
Verify the existence of any required static display text in the report
Prompts Check
Prompts are used to filter the data in the reports as needed. They can be of different types, but the most common type of prompt is a select list or dropdown with a list of values. Some of the key tests for prompts are :
Verify that all the prompts are available as per requirements. Also, check if the type of prompt matches the design specification.
For each prompt, verify the label and list of values displayed (where applicable).
Apply each prompt and verify that the data in the report is getting filtered appropriately.
Verify the default prompt selection satisfies the report or dashboard page design specification.
Report Data Accuracy Check
Verify that the data shown in the report is accurate. This check is a vital aspect of the report’s functional testing.
Cross-check the report with data shown in a transactional system application that is trusted by the users as the source of truth for the data shown in the report.
Come up with an equivalent database query on the target and source databases for the report. Compare the results from the queries with the data in the report.
Review the database query generated by the report for any issues.
Apply reports prompts and validate the database query generated by the report as well as the query output.
Drilldown Report Checks
It is common to have links to drill down reports in a report so the user can navigate those reports for further details. Links to these reports can be at the column or heading levels. For each link to the drill-down report, verify the following items :
Verify that the counts are matching between the summary and detail report where appropriate.
Verify that all the summary report prompts are applied to the detail report.
Check if the links to the detail report from the summary report are working from charts, tables, and table headings.
Verify the database SQL query for the drill-down report is as expected.
Report Performance Checks
Verify that the reports and dashboard page rendering times are meeting SLA requirements. Test the performance for different prompt selections. Perform the same checks for the drill-down reports.
Browser Checks
Browser compatibility of the reports is often dictated by the support of these browsers by the BI tool being used for the BI project. Any custom Java script additions to the report or dashboard page can also result in browser-specific report issues.
BI Security Testing
Like any other web application, BI applications also have authentication and authorization security requirements. BI applications are often integrated with single sign-on or embedded with other transactional applications. It is important to test the security aspects of the BI application just like other web applications.
Report Access Security
This test aims to validate that the BI user's access to the BI reports, subject areas and dashboards is limited according to their access levels. Role-based security in the BI tool generally controls access to the reports.
Understand how access to reports is different for different roles.
Identify users with those roles for testing.
Login as these users and validate access to the reports and subject areas.
Data Security
In this form of security, different users have access to a report, but the data shown in the report is different based on the person running the report.
Single Sign-on Security
Single sign-on is often used as the authentication mechanism for BI applications in large enterprises. This testing aims to ensure that users can access BI applications using their single sign-on access (or Windows authentication).
Integrated Security
BI Applications are sometimes embedded as part of other transaction system applications using a common authentication mechanism. This integration needs to be tested for different users.
BI Regression Testing
BI tools make it easy to create new reports by automatically generating the database query dynamically based on a predefined BI Model. This presents a challenge from a regression testing standpoint because any change to the BI Model can potentially impact existing reports. Hence it is important to do a complete regression test of the existing reports and dashboards whenever there is an upgrade or change in the BI Model.
BI Stress Testing
BI Stress testing is similar to testing of any web-based application testing. The objective is to simulate concurrent users accessing reports with different prompts and understand the bottlenecks in the system.
Simulating User Behavior
A typical BI user will log into the system, navigate to reports (or dashboards), apply prompts, and drill down to other reports. After the report is rendered, the BI User reviews the data for a certain time called think time. The BI user eventually logs out of the system. The first step in conducting a stress test is to identify a list of the most commonly used reports or dashboards for the testing.
Simulating Concurrent User Load
Conducting a stress test requires concurrently simulating the above BI user behaviour for different user loads. So it is important to have a list of different user logins for the stress test. When executing the reports, each user can pick a different set of prompt values for the same report. The stress test should be able to randomize each user's prompt selection to generate a more realistic behaviour.
BI Cache
Most of the BI tools support a caching mechanism to improve the performance of the reports. Database queries and the data blocks used to generate the results are also cached in databases. The question that frequently comes up is whether the cache should be turned off for stress testing. While turning off caching is a good way to understand system bottlenecks, we recommend performing the stress test with the caching turned on because it is closer to what a production system would look like. The following points should be kept in mind to reduce the impact of caching :
Include a large set of reports and dashboard pages.
Randomize prompt values for a given report or dashboard page to request the same report with different filter conditions.
User a large pool of user login so that different user-based security is applied during the execution.
Stress testing is an iterative process. When the first round of stress tests is conducted, a particular component of the system (e.g. database cache) might max out and bring down the response times. Once this bottleneck has been addressed, another round of stress tests might find another bottleneck. This process must continue until the target concurrent user load and report performance SLAs are met.
Performance Measurements
There are several performance data points that need to be captured while running a stress test:
Initial and final response time for each of the report and dashboard pages.
Time spent for each request in the database and in the BI tool.
CPU and memory utilization in the server machines (BI Tool and database).
Load balancing across all the nodes in a cluster.
The number of active sessions and the number of report requests.
Busy connection count in database Connection pool and current queued requests.
Network load.
Database cache and disk reads.



